Concepts
Liftbridge is a durable stream augmentation for NATS, so it's important to have a good grasp of the key concepts in NATS. NATS is a pub/sub messaging system that centers around the concept of subjects. Clients publish messages to subjects and receive messages from subscriptions to subjects.
Liftbridge is currently compatible with version 1.x.x of the NATS protocol.
Streams and Partitions
Fundamentally, Liftbridge is just a consumer of NATS subjects. It receives messages received from NATS subjects and records them in a durable log which is then exposed to subscribers. Specifically, Liftbridge centers around the concept of a stream, which is a durable message stream attached to a NATS subject. A stream consists of one or more partitions, which are ordered, replicated, and durably stored on disk and serve as the unit of storage and parallelism in Liftbridge.
Liftbridge relies heavily on the filesystem for storing and caching stream messages. While disks are generally perceived as slow, they are actually quite fast in the case of linear reads and writes which is how Liftbridge operates. As shown in this ACM Queue article, sequential disk access can be faster than random memory access. Liftbridge also uses memory mapping for message indexing to allow for efficient lookups.
{kind=link}
By default, partition data is stored in the /tmp/liftbridge/<namespace>
directory where namespace is the cluster namespace used to implement
multi-tenancy for Liftbridge clusters sharing the same NATS cluster. The
default namespace is liftbridge-default. It can be changed with the
clustering.namespace
configuration. Additionally, the full data directory can be overridden with the
data.dir configuration.
Streams have a few key properties: a subject, which is the corresponding NATS subject, a name, which is a human-readable identifier for the stream, and a replication factor, which is the number of nodes the stream's partitions should be replicated to for redundancy. Optionally, there is a group which is the name of a load-balance group for the stream to join. When there are multiple streams in the same group, messages will be balanced among them.
Use Case Note
The common use case is as follows. A typical subject is the command subject (comparable to a Kafka topic) of the CQRS pattern. The corresponding log created by this subject is the implementation of the event-sourcing pattern. The response of a command being put on a subject is a microservice worker reading that command off the subject and executing the command. Subsequently, the result of this activity is then posted to another subject, perhaps for downstream analytical reporting purposes. This enables the Query in the CQRS pattern. A careful reader saw the above remarks on partitioning, replication factor, redundancy, load-balance groups. These choices will impact this example with microservice workers, since the order of messages and guarantees on replication will be affected by them.
Refer to these references for further information on CQRS and event sourcing.
There can be multiple streams attached to the same NATS subject, but stream names must be unique within a cluster.
By default, streams have a single partition. This partition maps directly to the stream's NATS subject. If a stream has multiple partitions, each one maps to a different NATS subject derived from the stream subject. For example, if a stream with three partitions is attached to the subject "foo", the partitions will map to the subjects "foo", "foo.1", and "foo.2", respectively. Please note the naming convention on these subjects linked to partitions.
Each partition has its own message log, leader, and set of followers. To reduce resource consumption, partitions can be paused. Paused partitions are subsequently resumed once they are published to.
Message streams and partitions are sometimes referred to as the data plane. This is in contrast to the control plane, which refers to the metadata controller.
Write-Ahead Log
Each stream partition is backed by a durable write-ahead log. All reads and writes to the log go through the partition leader, which is selected by the cluster controller. The leader sequences each message in the partition and sends back an acknowledgement to publishers upon committing a message to the log. A message is committed to the log once it has been replicated to the partition's in-sync replica set (ISR).
Architect's Note
A note on configuring for durability and preventing message loss. If a message is published with the
LEADERack policy (the default policy), an ack is sent back to the client as soon as the leader has stored the message. If a message is published with theALLack policy, the ack is sent only after all members of the ISR have stored it. Thus, if the ISR is unavailable, no ack will be sent indicating there's no guarantee the message was committed. A minimum ISR size can also be configured to provide a high level of durability, but this creates an implicit trade-off with availability. See documentation here on configuring for high availability and consistency.
Consumers read committed messages from the log through a subscription on the partition. They can read back from the log at any arbitrary position, or offset. Additionally, consumers can wait for new messages to be appended to the log.
Use Case Note
The interested reader will identify a typical consumer to be a stateless microservice worker. The offset parameter is of special interest should one have consumers with different and independent purposes. For example, a reporting consumer could have lower priority when loads are high and an operational consumer have higher priority, resulting in different offsets on the same subject.
Consequently, different consumers are able to process at their own speed. Also, a paused or starved consumer, potentially a Pod in Kubernetes, like the potential reporting consumer, could easily pick up where it left off when things slow down. Consumers may use cursors to track their state, i.e. the offset. However, the preferred pattern for tracking state is to use consumer groups. Consumer groups can be used to implement durable consumers, which transparently handle cursor management.
Scalability
Liftbridge is designed to be clustered and horizontally scalable. The controller is responsible for creating stream partitions. When a partition is created, the controller selects replicas based on the stream's replication factor and replicates the partition to the cluster. Once this replication completes, the partition has been created and the leader begins processing messages.
As mentioned above, there can exist multiple streams attached to the same NATS subject or even subjects that are semantically equivalent e.g. "foo.bar" and "foo.*". Each of these streams will receive a copy of the message as NATS handles this fan-out.
Use Case Note
Since multiple streams can be attached to the same subject or overlapping subjects, this lends itself to creating streams on the same data for different purposes or use cases where there might be different operational concerns.
An example of this might be creating a stream attached to the subject
request.*which acts as an audit log of all operations. Other streams would then be attached to more granular subjects used to perform the actual operations, such asrequest.temperature,request.humidity, andrequest.precipitation.
With this in mind, we can scale linearly by adding more nodes to the Liftbridge cluster and creating more streams which will be distributed amongst the cluster members. This has the advantage that we don't need to worry about partitioning so long as NATS is able to withstand the load. The downside of this is that it results in redundant processing of messages. Consumers of each stream are all processing the same set of messages. The other issue is because each stream is independent of each other, they have separate guarantees. Separate leaders/followers, separate ISRs, and separate acking means the logs for each stream are not guaranteed to be identical, even though they are bound to the same NATS subject.
To accommodate this, streams are partitioned. By default, a stream consists of just a single partition, but multiple partitions can be created for increased parallelism. Messages can then be delivered to partitions based on their key, in a round-robin fashion, randomly, or with some other partitioning strategy on the client.
Architect's Note
Please note that ordering within the partition is upheld but not across partitions. This means that the partitioning strategy is of high importance since an aggregated state cannot be achieved for an order-dependent consumer subscribing to many streams. A consumer needing total ordering of events can only subscribe to many streams if and only if the events are uncorrelated/independent between the partitions (and thus have order within a partition).
An architect would pay particular interest to ensuring independent and stateless workers when applying domain-driven design. As a general rule, requiring a strict global ordering of messages will severely limit the scalability and performance of a system.
Use Case Note
One of the main use cases for partitions is implementing horizontal scalability. For example, imagine we are implementing analytical processing of clickstream events for a website. To scale this system, we could partition the stream by user id which would allow us to distribute load across the cluster while retaining event ordering per user.
Additionally, streams can join a named load-balance group, which load balances messages on a NATS subject amongst the streams in the group. Load-balance groups do not affect message delivery to other streams not participating in the group. Load-balance groups are for distributing messages from a subject amongst a group of streams.
Architect's Note
Note that the intent of load-balance groups could also be achieved using a partitioned stream with a random or round-robin partitioning strategy. However, partitioning assumes a user has already "bought in" to Liftbridge streams as an architectural component. But imagine a case where there is a pre-existing NATS subject that Liftbridge-agnostic services are already publishing to, and we want to turn that NATS subject into a durable log that Liftbridge-aware services can consume. We could attach a single stream to the subject, but if it's high volume, we might need a load-balance group to distribute the load across a set of streams.
Partition replicas in Liftbridge primarily serve as a mechanism for high availability by providing redundancy of stream data. By default, reads go through the partition leader. However, consumers can opt-in to reading from any member of the partition's ISR, including followers, for further scale out.
The diagram below shows a cluster of three servers with a set of streams. Partitions in yellow indicate the server is the leader for the partition.
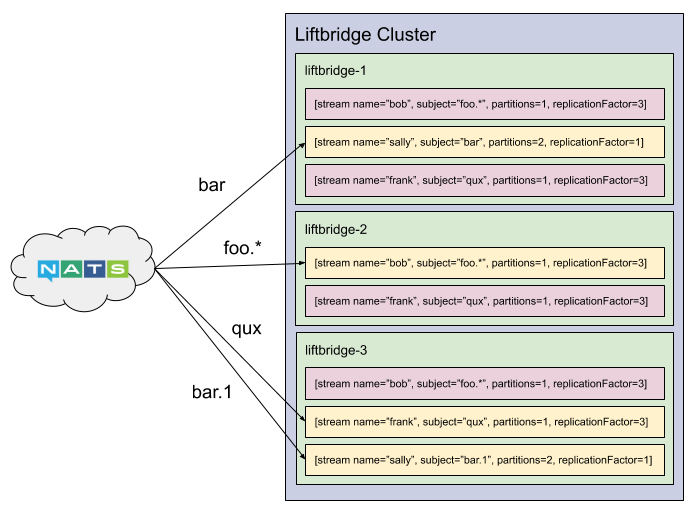
Refer to Configuring for Scalability for details on scaling the control plane.
In-Sync Replica Set (ISR)
The In-Sync Replica set (ISR) is a key aspect of the replication protocol in Liftbridge. The ISR consists of the set of partition replicas that are currently caught up with the leader. It is equivalent to the ISR concept in Kafka, and the replication protocol works very similarly.
In order for a message to be committed to a partition's write-ahead log, it must be acknowledged by all brokers in the ISR. To prevent a single slow broker from blocking progress, replicas that fall too far behind the leader are removed from the ISR. The leader does this by making a request to the controller. In this case, the cluster enters an under-replicated state for the partition.
Being "too far behind" is controlled by the replica.max.lag.time
configuration. This refers to both the maximum amount of time a replica can go
without making a replication request before it's removed and the amount of time
that can pass without being fully caught up with the leader before it's
removed. When a removed replica catches back up with the leader's log, it is
added back into the ISR and the cluster goes back into its fully replicated
state.
Under normal conditions, only a replica from the ISR can be elected the leader of a partition. This favors data consistency over availability since if the ISR shrinks too far, there is a risk of being unable to elect a new leader.
Acknowledgement
Acknowledgements are an opt-in mechanism to guarantee message delivery. If a
message envelope has an AckInbox, Liftbridge will send
an ack to this NATS inbox once the message has been committed. This is used to
ensure at-least-once delivery.
Messages can also have an optional CorrelationId, which is a user-defined
value which is also set on the server ack to correlate it to a published
message.
There are a couple of things to be aware of with message acknowledgements.
First, if the publisher doesn't care about ensuring its message is stored, it
need not set an AckInbox. Second, because there are potentially multiple
(or no) streams attached to a NATS subject (and creation of streams is
dynamic), it's not possible for the publisher to know how many acks to expect.
This is a trade-off we make for enabling subject fan-out and wildcards while
remaining scalable and fast. We make the assertion that if guaranteed delivery
is important, the publisher should be responsible for determining the
destination streams a priori. This allows attaching streams to a subject for
use cases that do not require strong guarantees without the publisher having to
be aware. Note that this might be an area for future improvement to increase
usability. However, this is akin to other similar systems, like Kafka, where
you must first create a topic and then you publish to that topic.
Use Case Note
A common use case for a producer not caring if the ack is returned or not is an IoT device or sensor. This means that for the sensor, it is not important to know if Liftbridge indeed recorded the event. For a more regulated system, one could assume acknowledgements are important to the producer since the recorded truth now resides within Liftbridge, as is the case in an event-sourced system.
Subscription
Subscriptions are how Liftbridge streams are consumed. A client subscribes to a stream partition and specifies a starting offset to begin consuming from. At this point, the server creates an ephemeral data stream for the client and begins sending messages to it. Once it consumes up to the end of the log, the server will wait for more messages to be published until the subscription is closed by the client.
Subscriptions are not stateful objects. When a subscription is created, there is no bookkeeping done by the server, aside from the in-memory objects tied to the lifecycle of the subscription. As a result, the server does not track the position of a client in the log beyond the scope of a subscription. Instead, Liftbridge provides a cursors API which allows consumers to checkpoint their position in the log and pick up where they left off. The cursors API is used by stateful consumer groups which provide a more managed solution to fault-tolerant consumption of streams.
Architect's Note
This ties back to the previously described reporting worker starved but clinging to an offset so as not to lose probable state. With cursors, the reporting worker can be restarted without state but can resume from where it left off due to state stored by the server via the cursors API. With consumer groups, which maintain state, this would be entirely transparent to the consumer.
Stream Retention and Compaction
Streams support multiple log-retention rules: age-based, message-based, and size-based. This, for example, allows semantics like "retain messages for 24 hours", "retain 100GB worth of messages", or "retain 1,000,000 messages".
Additionally, Liftbridge supports log compaction. Publishers can, optionally, set a key on a message envelope. A stream can be configured to compact by key. In this case, it retains only the last message for each unique key. Messages that do not have a key are always retained.
Architect's Note
From an architectural point of view, the choice here is to compact as much as possible without losing state (aggregation of events). Lineage is taken care of by the stream log if stored, for example, in an S3 bucket.
Consumer Groups
Consumer groups provide higher-level consumer functionality that can be used to solve several related problems:
- Provide a mechanism for clients to track their position in a stream automatically, i.e. "durable" consumers. This builds on cursors such that cursor management is transparent to users.
- Provide a mechanism for distributed, fault-tolerant stream consumption.
- Provide a mechanism for coordinating and balancing stream consumption by managing partition assignments for consumers.
- Provide a mechanism for consuming multiple streams (and/or partitions) in aggregate.
When a consumer in a consumer group fails, the group's coordinator will reassign the partitions the failed consumer was subscribed to to another member of the group. This allows for fault-tolerant consumption of streams. Consumers will automatically (or, if configured, explicitly), checkpoint their position in the partitions they are consuming such that if they fail, they or another consumer in the group can pick up where they left off.
Group coordinators are also highly available. If a server acting as the group coordinator becomes unavailable, the consumers will report the coordinator as failed to the controller, prompting a new coordinator to be selected.
See the consumer groups documentation for more information.
Activity Stream
The activity stream is a Liftbridge stream that exposes internal meta-events that have occurred in the cluster such as streams being created, deleted, paused, or resumed. This allows clients to dynamically react to changes in cluster state. See the activity stream documentation for more information.
Controller
The controller is the metadata leader for the cluster. Specifically, it is the Raft leader. All operations which require cluster coordination, such as creating streams, expanding ISRs, shrinking ISRs, or electing stream leaders, go through the controller and, subsequently, Raft to ensure linearizability. Raft automatically handles failing over the controller in the event of a failure for high availability.
Note that in order for the controller to make progress, a quorum (majority) of the brokers must be running.
Controller is also referred to as "metadata leader" in some contexts. There is only a single controller (i.e. leader) at a given time which is elected by the Liftbridge cluster. The concept of the metadata cluster is sometimes referred to as the control plane. This is in contrast to the data plane, which refers to actual message data, i.e. streams and partitions.
Architect's Note
Guidance on cluster size is use-case specific, but it is recommended to run an odd number of servers in the cluster, e.g. 3 or 5, depending on scaling needs. Ideally, cluster members are run in different availability zones or racks for improved fault-tolerance.
It is also important to note that, by default, all servers in the cluster participate in the Raft consensus group. This has implications on the scalability of the cluster control plane, which can be addressed by setting
clustering.raft.max.quorum.sizeto limit the number of nodes that participate in the Raft group. See Configuring for Scalability for more information.
Message Envelope
Liftbridge extends NATS by allowing regular NATS messages to flow into durable
streams. This can be completely transparent to publishers. However, it also
allows publishers to enhance messages by providing additional metadata and
serializing their messages into envelopes. An
envelope allows publishers to set things like the AckInbox, Key, Headers,
and other pieces of metadata.
Concurrency Control
Streams support control concurrency publishes. This is achieved by sending ExpectedOffset
on every publish request. The server may check and only approve message that has correct
ExpectedOffset. It faciliates the control when multiple clients publish to the same stream.
This feature enables complex use cases such as:
- Idempotent publish
- Use the stream as commitlog
This behavior may be enabled by configuration
This may be used in tandem with API FetchPartitionMetadata to retrieve partition's metadata.
Server-Side Encryption
Streams support the encryption of messages' values on the server side for extra security and data governance concerns.
This behavior may be enabled by configuration.
Upon initilization of a partition, a random AES key is generated and the message is encrypted using that key
(called the Data Key).
The generated key is then wrapped using advanced key wrapping algorithm proposed in RFC5649.
The encrypted message is stored alongside the wrapped DEK key in the commit log.
Further Reading
A final note is to read "Designing Event-Driven Systems" by Ben Stopford for inspiration.